
Some actions to reduce storage billing nearly 80% at GCS
Introduction
At cotatenis, we’re developing a price comparison site for sneakers for Brazilian online stores. As usual, this kind of business relies heavily on data collection across several online stores.
The cost of storage technology has dropped steadily in recent years. Despite that, at this early stage of our business cost always plays a major concern for the health of our company.
Thus, with that in mind, we have seen our storage costs rapidly rising during our development of the new web crawlers for our platform. That’s said, in our data collection stage, we collect all available data for each product that will be stored in our storage.
In that sneakers data, we have a lot of images for each product, and our first web crawlers were not yet prepared to reduce storage costs. For instance, in each spider run, we saved all pictures for each product that already exists or not in our database.
Our data lake currently is hosted on GCP and we’re using Google Cloud Storage (GCS) to build it. For clarity, at GCS all kinds of actions can be classified into three types: Class A, Class B, and Free operations.
I have to inform you that class A operations are the most expensive ones. So, for illustration, in the standard storage, they cost $0.05 per 10.000 operations, in contrast with the B type that only cost $0.004 per 10.000 operations, which is almost 13 times cheaper.
For the readers who are willing to learn more about GCS, I strongly recommend the documentation here. So, maybe are you asking why I am telling you about this type of operation in GCS, right?
So, when we save or overwrite any file in GCS we’re using a class A operation, which is the most expensive as I told you before. When we looked at our data gathering process our web crawlers are overwriting several files each time they are started and this is far away from optimal in terms of cost management.
Let’s get started to dig into our storage costs at cotatenis. The following picture is our storage bill for October 2021 and we’ll use that bill as our starting point for our analysis. We chose that one because it was the last month that we ran our spiders without any modifications for reducing costs.
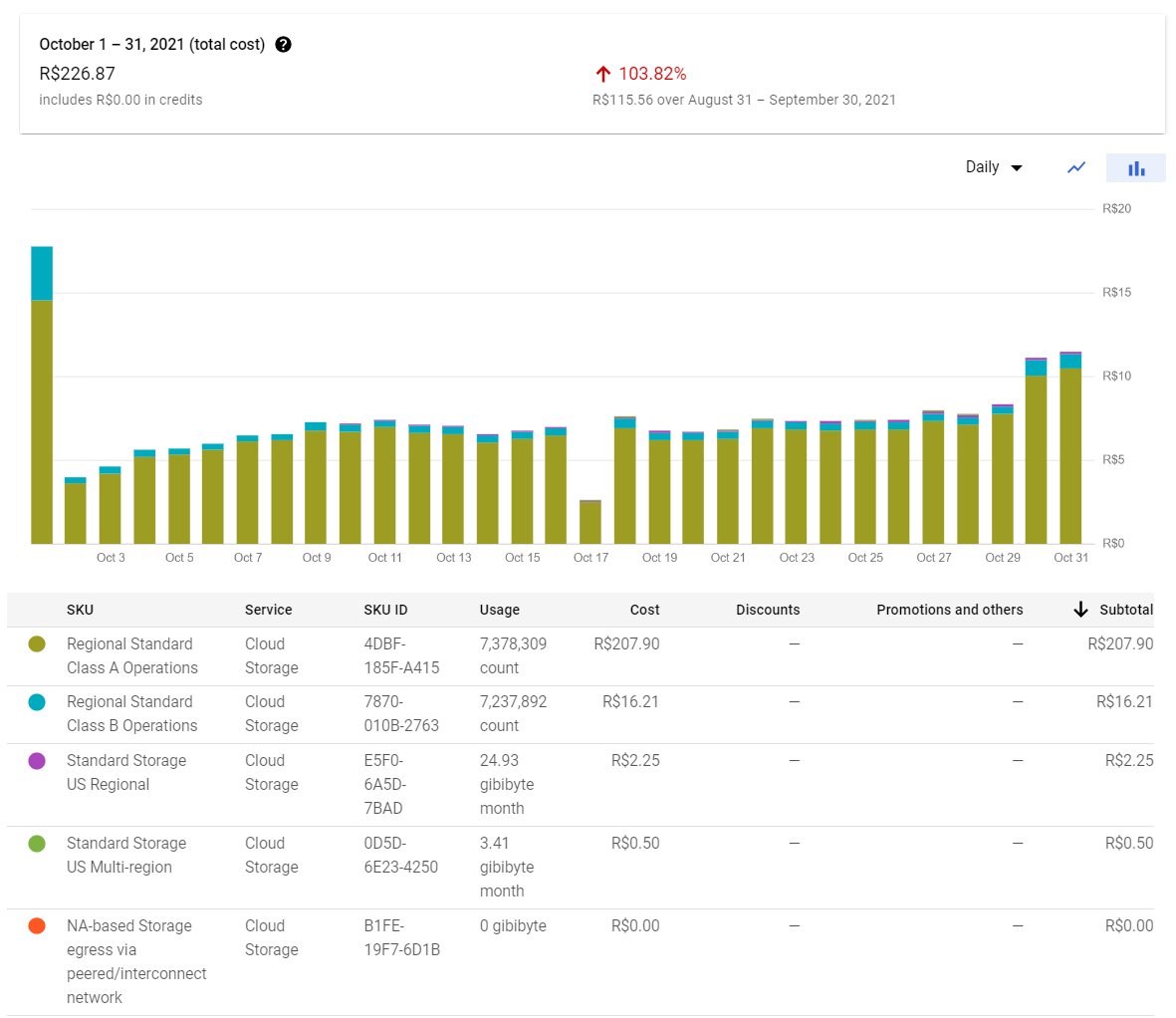
As you can see almost 92% of our storage cost is due to class A operations. Hence, is very obvious where we need to look to reduce our storage bill.
Putting a magnifier at our codebase
Here at cotatenis we’ve built our web crawlers using scrapy.
We’ve looked at the parameter IMAGES_EXPIRES that is responsible for avoiding downloading images that were downloaded recently, but for a reason that we’re not sure yet when we set up our IMAGES_STORE to Google Cloud Storage, this configuration does not have behaved like expected.
Thus, we need to customize our code to achieve the desired outcome. The following code was taken from the scrapy source hosted on GitHub. This chunk of code shows the method ´image_downloaded which is responsible to persist an image in the file system indicated in scrapy configuration.
def image_downloaded(self, response, request, info, *, item=None):
checksum = None
for path, image, buf in self.get_images(response, request, info, item=item):
if checksum is None:
buf.seek(0)
checksum = md5sum(buf)
width, height = image.size
self.store.persist_file(
path, buf, info,
meta={'width': width, 'height': height},
headers={'Content-Type': 'image/jpeg'})
return checksum
To achieve our goal we had a simple modification in this method and overwritten it. For the sake of clarity, we only added a file existence verification; if it does not exist, we’ll save it. In addition to that, according to this reply on stackoverflow this verification through .exists() is classified as a class B operation, thus much cheaper than we usually do when we overwrite a file (class A).
def image_downloaded(self, response, request, info, *, item=None):
"""
This modification verifies if the file (blob) already exists in our data lake, if not exists, save it.
"""
checksum = None
for path, image, buf in self.get_images(response, request, info, item=item):
if checksum is None:
buf.seek(0)
checksum = md5sum(buf)
# get the blob
blob = self.store.bucket.blob(self.store.prefix + path)
if not blob.exists(): #check if this blob already exists
width, height = image.size
self.store.persist_file(
path, buf, info,
meta={'width': width, 'height': height},
headers={'Content-Type': 'image/jpeg'})
return checksum
We’d applied this patch into our web crawlers along the first days of November 2021. In the following chart, it’s possible to identify our economy due primarily to the reduction of class A operations registered in our billing.
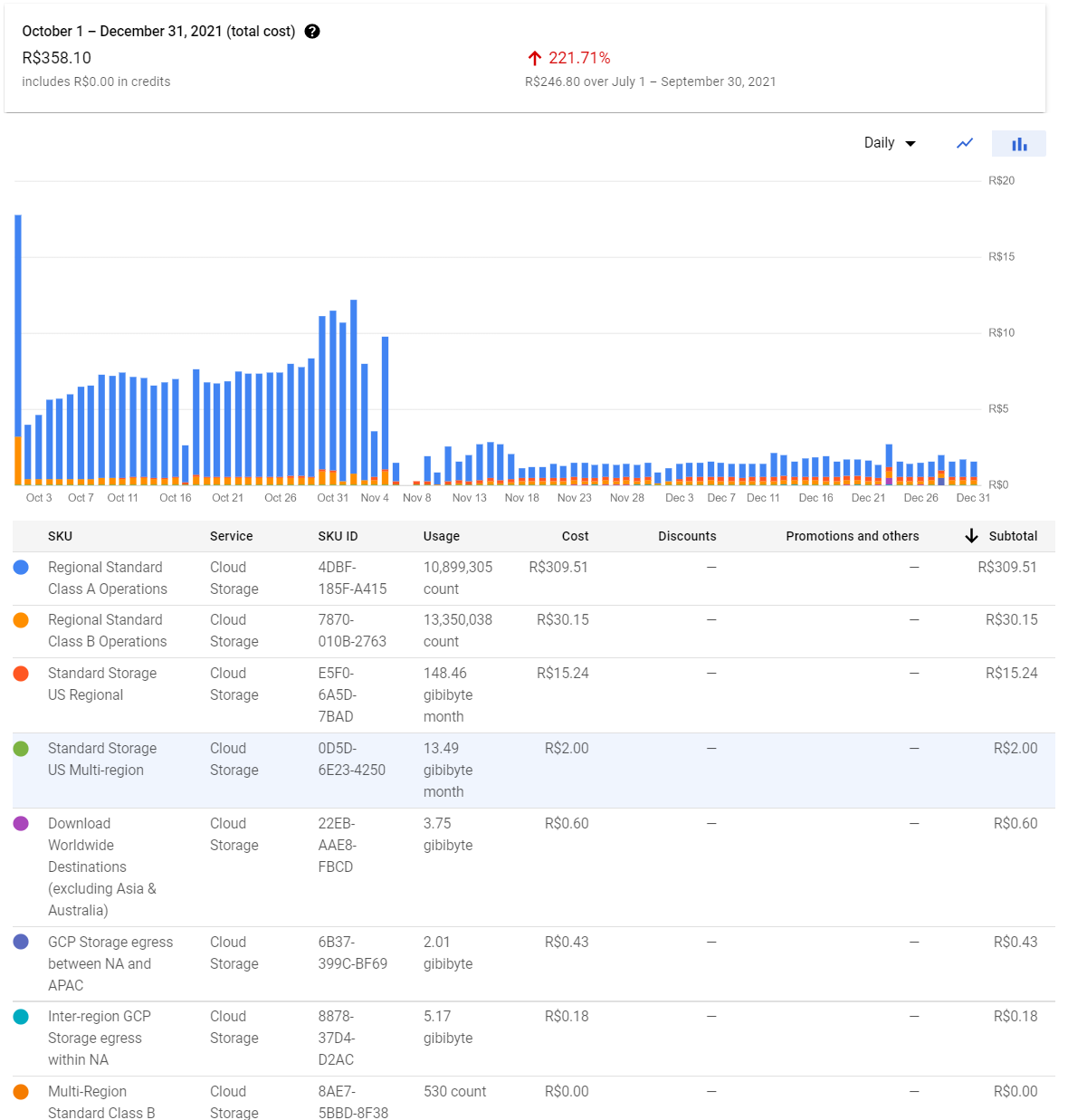
To better identify this improvement of our billing costs, I’ll split our storage costs by month.
- October (224.57 BRL)
- November (84.37 BRL)
- December (49.16 BRL)
Our data gathering processing was run along December entirely with this new code that we presented above. Therefore we achieve almost 80% of reduction in our storage billing in comparison with October which is our baseline.
I expect you have enjoyed this post as I had during my writing process. So, I hope that you have learned something from this material. See you next time! 🙂