
Serverless Web Scraping
1. Introduction
I have past the last several years learning about the data science field as well as software development techniques. However, is remarkable how cloud services are revolutionized how we’re working with technology in the last decade. Moreover, the several options of services to deploy apps in a fully managed way are remarkable. Google Cloud Platform has a service called Cloud Run which offers a serverless deployment based on containers that can scale in response to their use.
That’s said I’ve wondered how could a web scraper benefit from these services. First of all, many scrapers don’t run 24/7 and thus their host machines may not be being used optimally in terms of saving resources and thus money. We could think of other scenarios when a serverless deployment could fit with a web scraper, but let’s focus on our project for now.
2. Web Crawler
There is a amazing project called base dos dados which built a public data lake with data from several resources and I’m very excited to collaborate with them. For this purpose, I’ve decided to build a web scraper to collect data from fuel stations in Brazil available on this site. Thus, this will be our toy project to evaluate a serverless architecture for scrapy project.
2.1 Design our spider
Analyzing our site, we’ve conclude that it could be divided in three parts.
2.1.1 Home
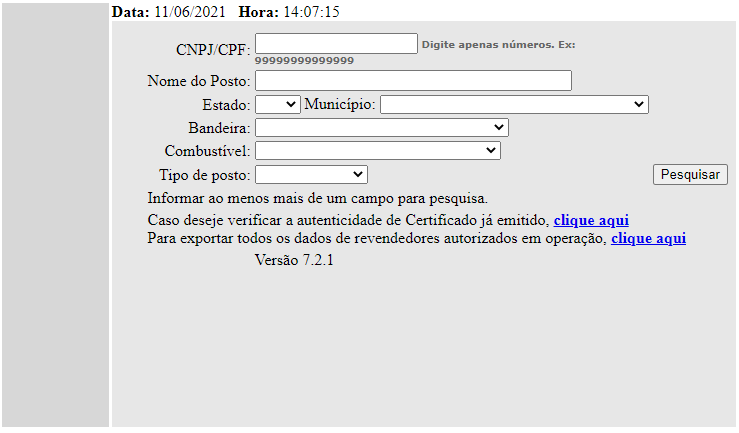
This is the home, where we can submit a form to query our search.
2.1.2 Results
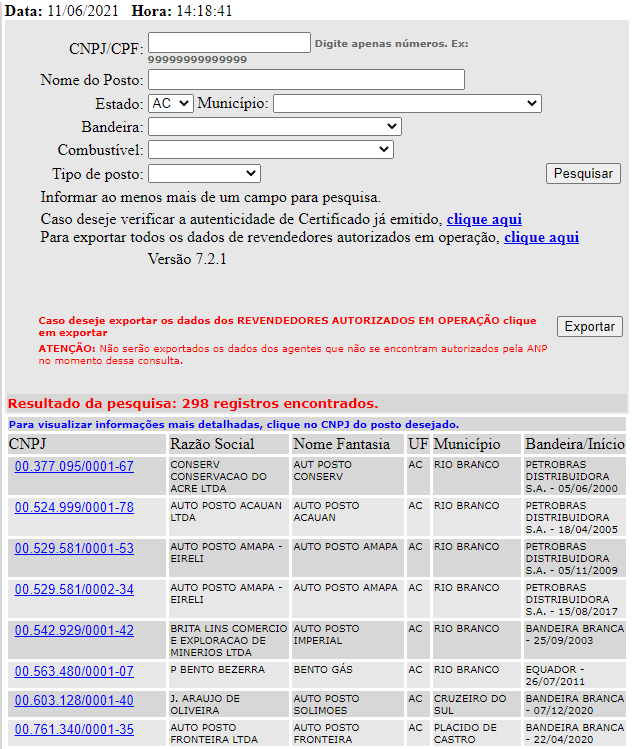
Our query on the home page - when occurs successfully - brings to this page, where are listed the results.
2.1.3 Details
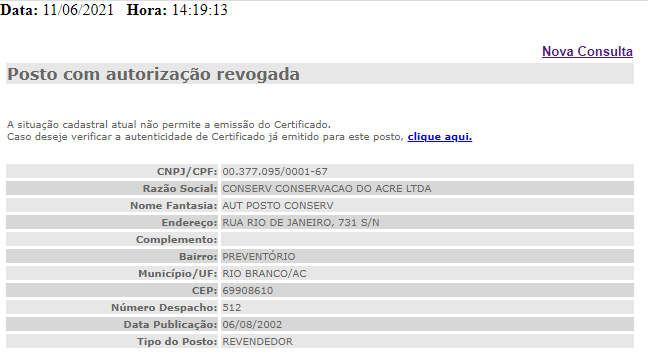
Each one of the results listed in the results page has a page with information details, which is our target in this web scraping.
2.2 Architecture
We’re going to divide responsibilities in this web scraping. Our first spider (TaskMakerSpider) will be in charge to make a POST request for the form located on the home page and then collect all parameters necessary to make a request to the details page. Our second duty is to collect all data available in details page, for that we’re built a second spider called FacilityDetailsSpider.
Our next goal was to build an API to initiate these crawlers. We’ve used fastapi for that and we created two endpoints that initiate each one of our crawlers. You may look below for more details the /details endpoint.
@crochet.run_in_reactor
@app.post("/details")
def collect_details(data: PubSubMessage):
message = data.message
# base64
b64payload = message.get("data")
payload = json.loads(base64.b64decode(b64payload).decode("utf-8"))
codes = payload.get("codes")
uf = payload.get("uf")
if not codes:
raise HTTPException(status_code=404, detail="codes not found.")
if not uf:
raise HTTPException(status_code=404, detail="uf not found.")
settings = get_project_settings()
settings_module_path = os.environ.get("SCRAPY_ENV", "fuelstations.settings")
settings.setmodule(settings_module_path)
configure_logging(settings)
runner = crawler.CrawlerRunner(settings)
_ = runner.crawl(FacilityDetailsSpider, **{"codes": codes, "uf": uf})
return {"status": "FacilityDetailsSpider has started."}
With those two endpoints available we finally can define our last pieces of this project. We’re going to use Cloud Scheduler to make a POST request for the endpoint /taskmaker which will be hosted in Cloud Run service. Once TaskMakerSpider finishes his run it will send a payload to a topic (fuel-station-data) on PubSub. We’ve configured a push subscription (fuel-station-data-sub) on this topic to forward every message received to the endpoint /details hosted as well in Cloud Run. Finally, our last milestone was to save your collected data into a table in Big Query.

It worth mentioning that a call to a service hosted in Cloud Run should be done its job in less than 15 minutes. For ensuring that constraints we’ve defined that TaskMakerSpider will split every group of parameters that will be sent to PubSub topic in chunks of 25, in this way we guarantee that FacilityDetailsSpider will be in charge to visit up to 25 URLs.
2.2.1 Scrapy Pipelines
TaskMakerSpider needs to send data collected on the results page to a PubSub topic. For that we’ve built PubSubPublisher a ItemPipeline to accomplish that.
class PubSubPublisher:
def __init__(self, project_name, topic_id, credentials_path) -> None:
try:
credentials_file = Path(credentials_path)
except TypeError:
credentials_file = os.environ.get("GCP_CREDENTIALS_PUBSUB")
else:
if not credentials_file.is_file():
print("File credentials for PubSub not found.")
sys.exit(1)
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = str(credentials_file)
self.project_name = project_name
self.topic_id = topic_id
@classmethod
def from_crawler(cls, crawler):
return cls(
project_name=crawler.settings.get("GCP_PROJECT_ID"),
topic_id=crawler.settings.get("PUBSUB_TOPIC_ID"),
credentials_path=crawler.settings.get("GCP_CREDENTIALS_PUBSUB"),
)
def open_spider(self, spider):
self.publisher = pubsub_v1.PublisherClient()
self.topic_path = self.publisher.topic_path(self.project_name, self.topic_id)
def process_item(self, item, spider):
payload = ItemAdapter(item).asdict()
payload = json.dumps(payload).encode("utf-8")
future = self.publisher.publish(self.topic_path, payload, origin="task_maker")
_id = future.result()
spider.logger.info(f"Message {_id} has sent for topic {self.topic_id}.")
Our data collected on the details page by FacilityDetailsSpider has needed to be sent to Big Query, for that we’ve built BQIngestor which is another ItemPipeline.
class BQIngestor:
def __init__(self, project_name, bq_table, credentials_path):
try:
credentials_file = Path(credentials_path)
except TypeError:
credentials_file = os.environ.get("GCP_CREDENTIALS_BQ")
if not credentials_file.is_file():
print("File credentials not found.")
sys.exit(1)
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = str(credentials_file)
self.project_name = project_name
self.bq_table = bq_table
def open_spider(self, spider):
self.bq_client = bigquery.Client(project=self.project_name)
@classmethod
def from_crawler(cls, crawler):
return cls(
project_name=crawler.settings.get("GCP_PROJECT_ID"),
bq_table=crawler.settings.get("BQ_TABLE"),
credentials_path=crawler.settings.get("GCP_CREDENTIALS_BQ"),
)
def process_item(self, item, spider):
payload = ItemAdapter(item).asdict()
payload = [payload]
errors = self.bq_client.insert_rows_json(
self.bq_table, payload, row_ids=[None] * len(payload)
)
if errors == []:
spider.logger.info(
f"We've scraped sucessly data for fuel station {item.get('cnpj')}."
)
else:
spider.logger.error(
"Encountered errors while inserting rows: {}".format(errors)
)
spider.logger.error(payload)
2.3 Dockerizing
We’ve created a Dockerfile to containerize our application and start-up our API.
FROM python:3.7.9-slim-buster as base
WORKDIR /app
FROM base as builder
ARG LOCAL_USER_ID=1000
ENV PORT=8000
ENV PIP_DEFAULT_TIMEOUT=100 \
PIP_DISABLE_PIP_VERSION_CHECK=1 \
PIP_NO_CACHE_DIR=1 \
PYTHONFAULTHANDLER=1 \
PYTHONHASHSEED=random \
PYTHONUNBUFFERED=1 \
GCP_PROJECT_ID=postos-anp\
GCP_CREDENTIALS_BQ=./fuelstations/credentials/credentials.json\
GCP_CREDENTIALS_PUBSUB=./fuelstations/credentials/pubsub_credentials.json\
GCP_BQ_TABLE=postos_anp.staging_postos_anp\
GCP_PUBSUB_TOPIC_ID=fuel-station-data
RUN adduser --system -u ${LOCAL_USER_ID:-1000} crawler && \
apt-get update && \
apt-get -qq -y install curl && \
apt-get install -y gnupg2
COPY requirements.txt ./
RUN pip install -r requirements.txt
COPY . .
RUN chown crawler /app
USER crawler
EXPOSE ${PORT}
CMD exec uvicorn --host 0.0.0.0 --port ${PORT} main:app
Our next goal is to create a docker image and push it to Cloud Registry. The following commands shows the Makefile that we built to do it.
APPNAME = postos_anp_crawler
VERSION = 0.5.3
PROJECT = postos-anp
publish:
@sudo docker build \
-t ${APPNAME}:${VERSION} . && \
docker tag ${APPNAME}:${VERSION} gcr.io/${PROJECT}/${APPNAME}:${VERSION} && \
docker push gcr.io/${PROJECT}/${APPNAME}:${VERSION}
git-release:
git add .
git commit -m "v$(VERSION)"
git tag v$(VERSION)
git push
git push --tags
With that done, we’ll push this image to Container Registry.
make publish
2.4 Initiator
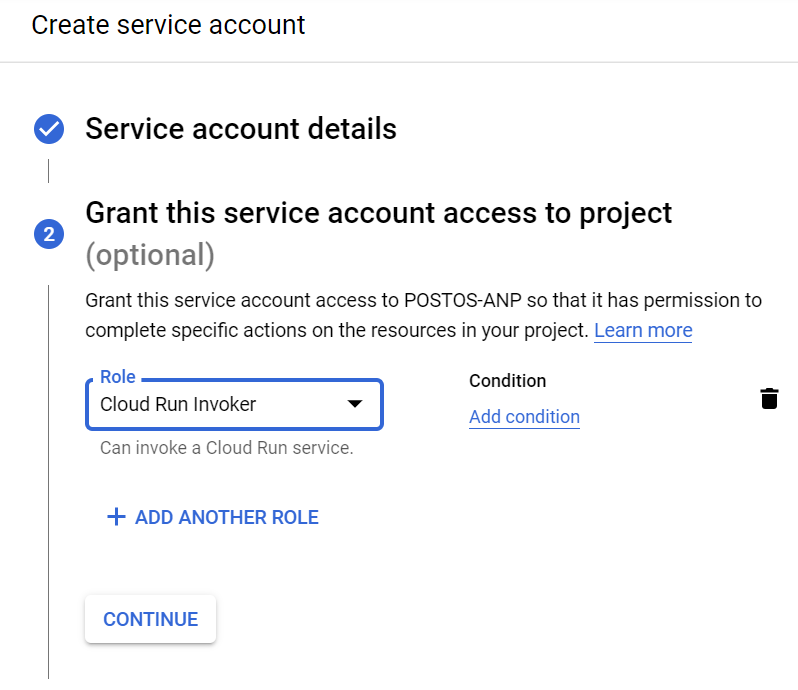
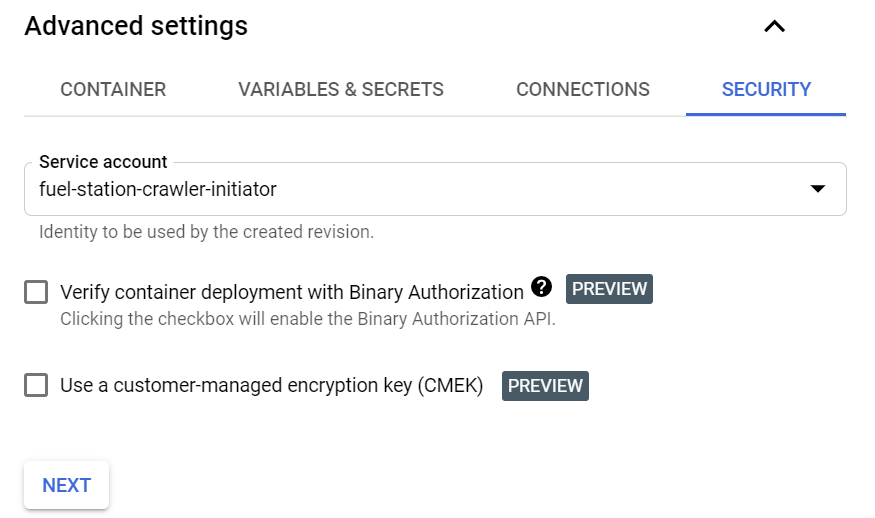
To continue our work we need to configure a service account with Cloud Run Invoker role. We’ve done that and named it fuel-station-crawler-initiator.
2.5 Deploy
2.5.1 Cloud Run
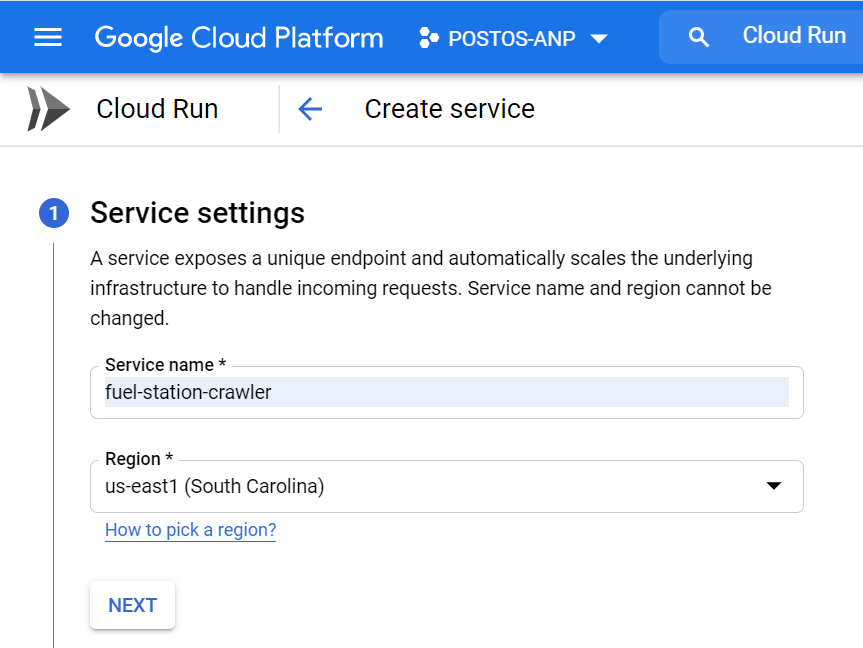
We’re going to use Cloud Run to deploy our API. For that, we must define a service name and pick up a region to host our service.
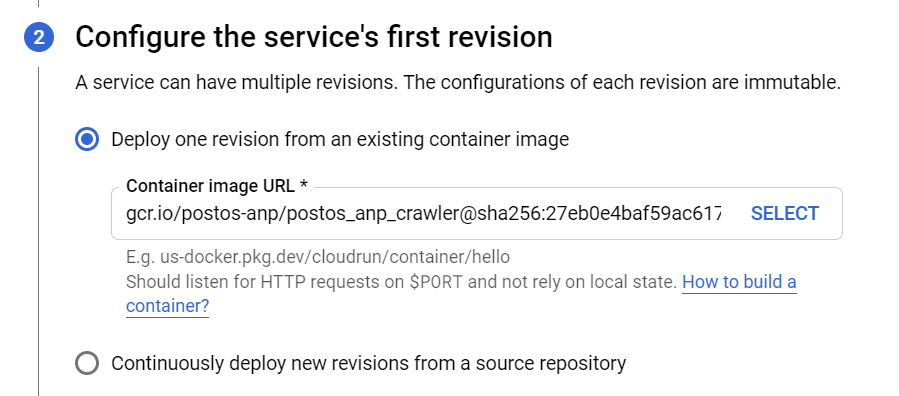
Then we select which image hosted on Cloud Registry we want to use.
Furthermore, we need to set up which port will be exposed by Cloud Run and this one must match the same port defined in Dockerfile.
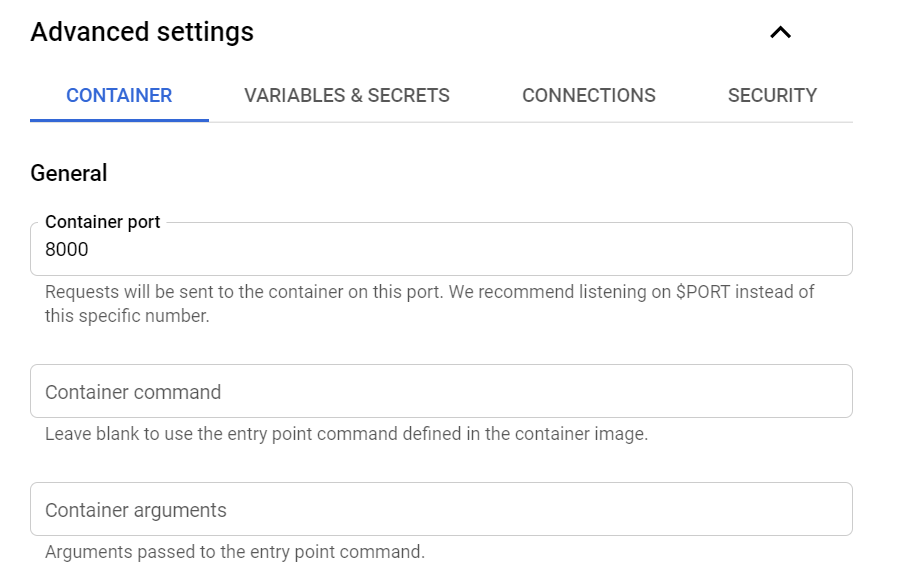
And then we need to set up which service account will be used to make calls to our service.
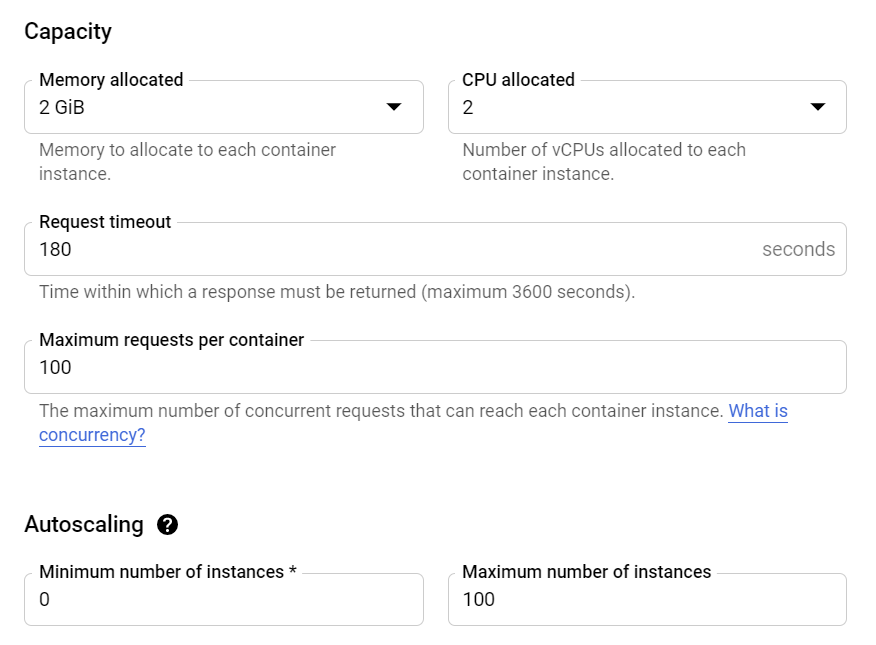
It’s worth mentioning that we could benefit from the cold start option offered by Cloud Run, in that way we will not be charged when this application doesn’t run. To use that option we need to set Minimum number of instances equal to 0.
Finally, we set up that will be needed authentication to access our application.
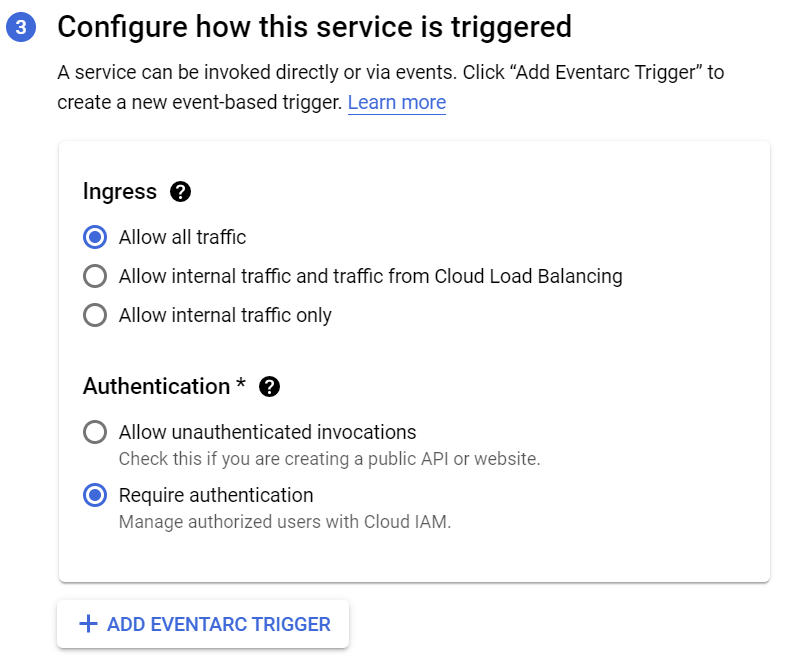
2.5.2 Cloud Scheduler
We’re going to create a schedule to collect every fuel station data for each federation unit of Brazil. The following example shows how to do it for collecting fuel station data belongs to Maranhão state.
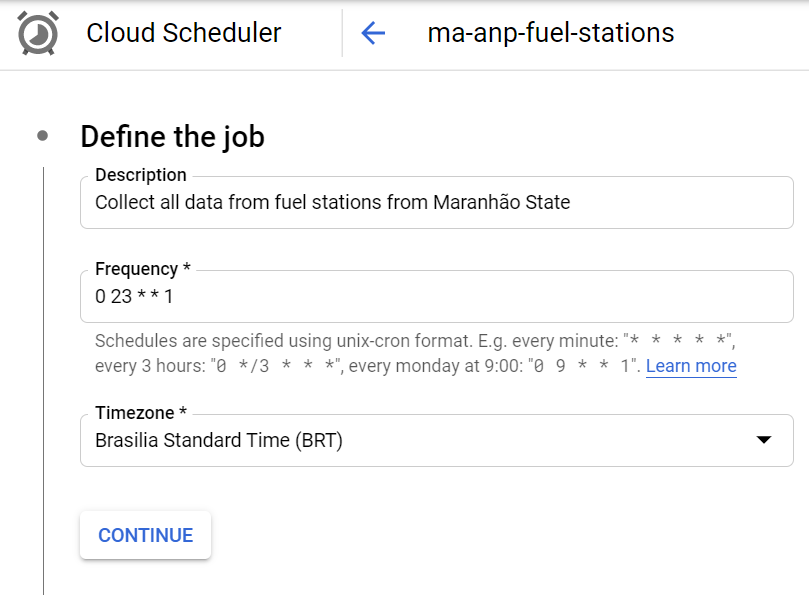
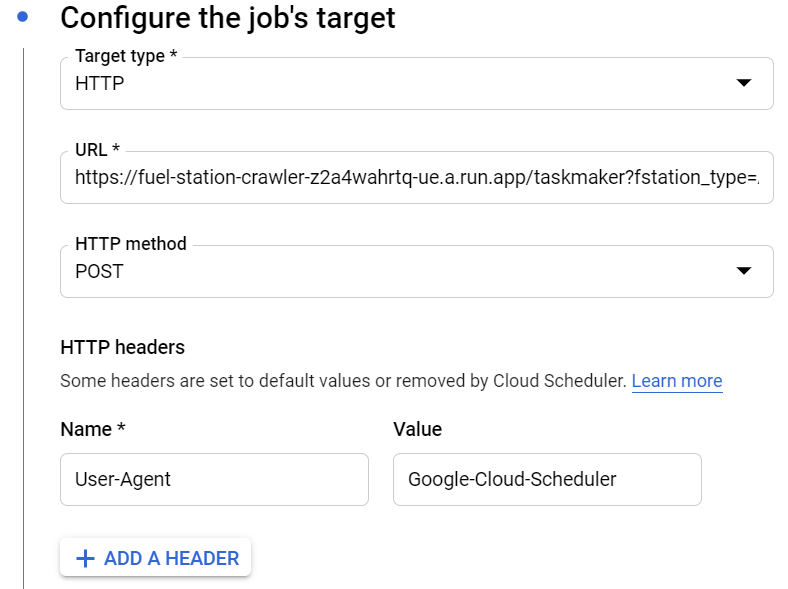
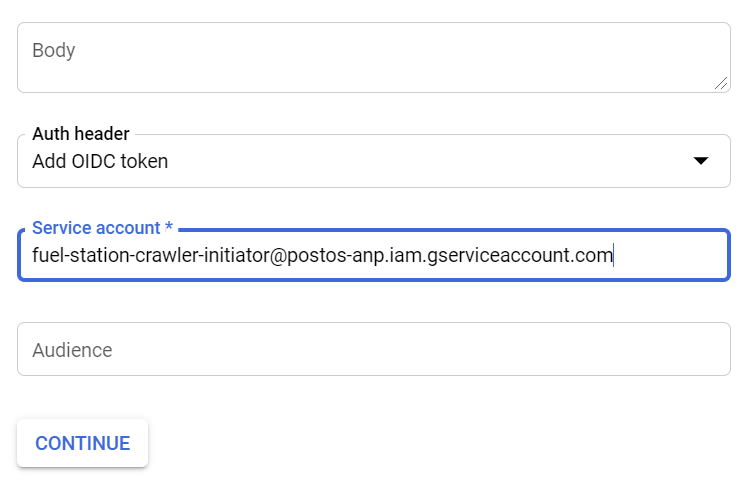
2.5.3 PubSub
After we’ve created a PubSub topic we need to configure a push subscription for this topic.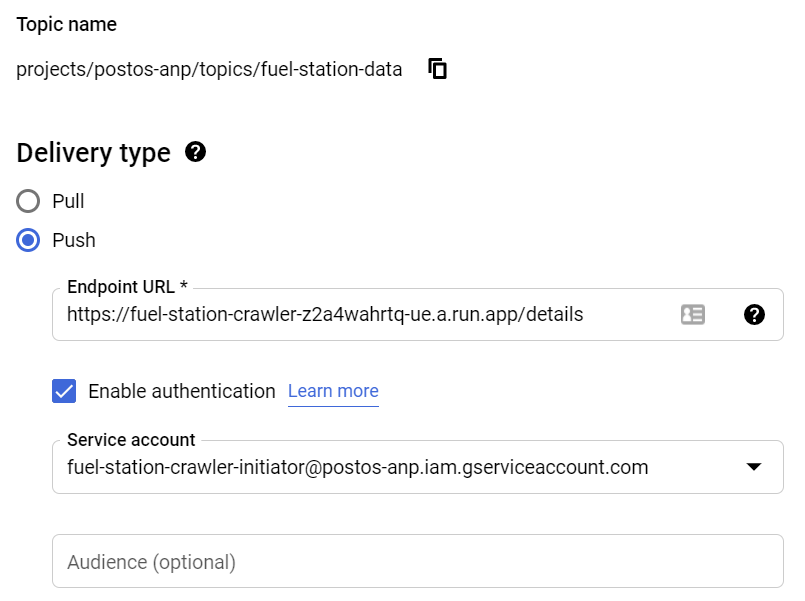
3. Trigger our crawlers
With all these configurations done, we can initiate our spiders through Cloud Scheduler. Along our crawlers are running we can use Cloud Logging to monitoring their working.
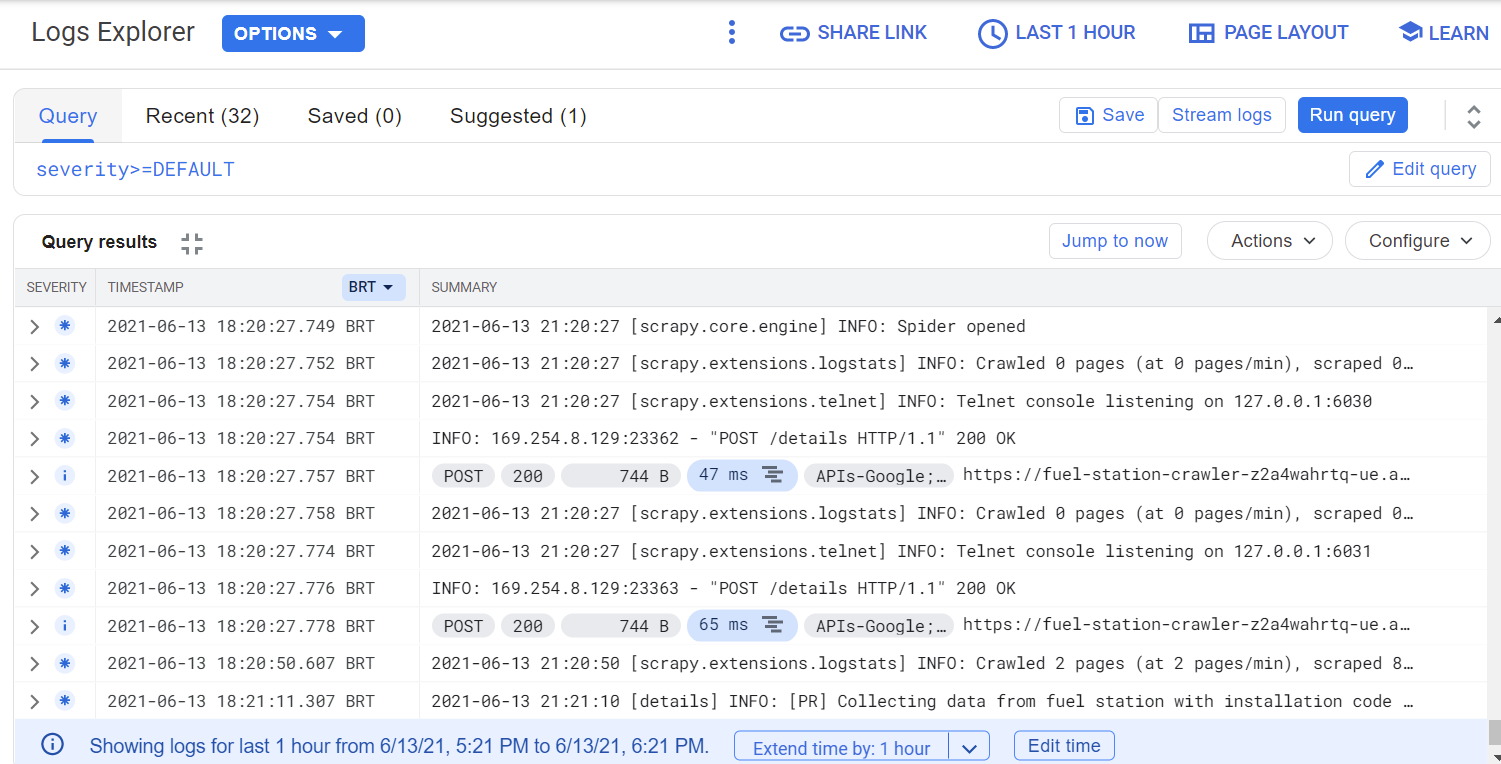
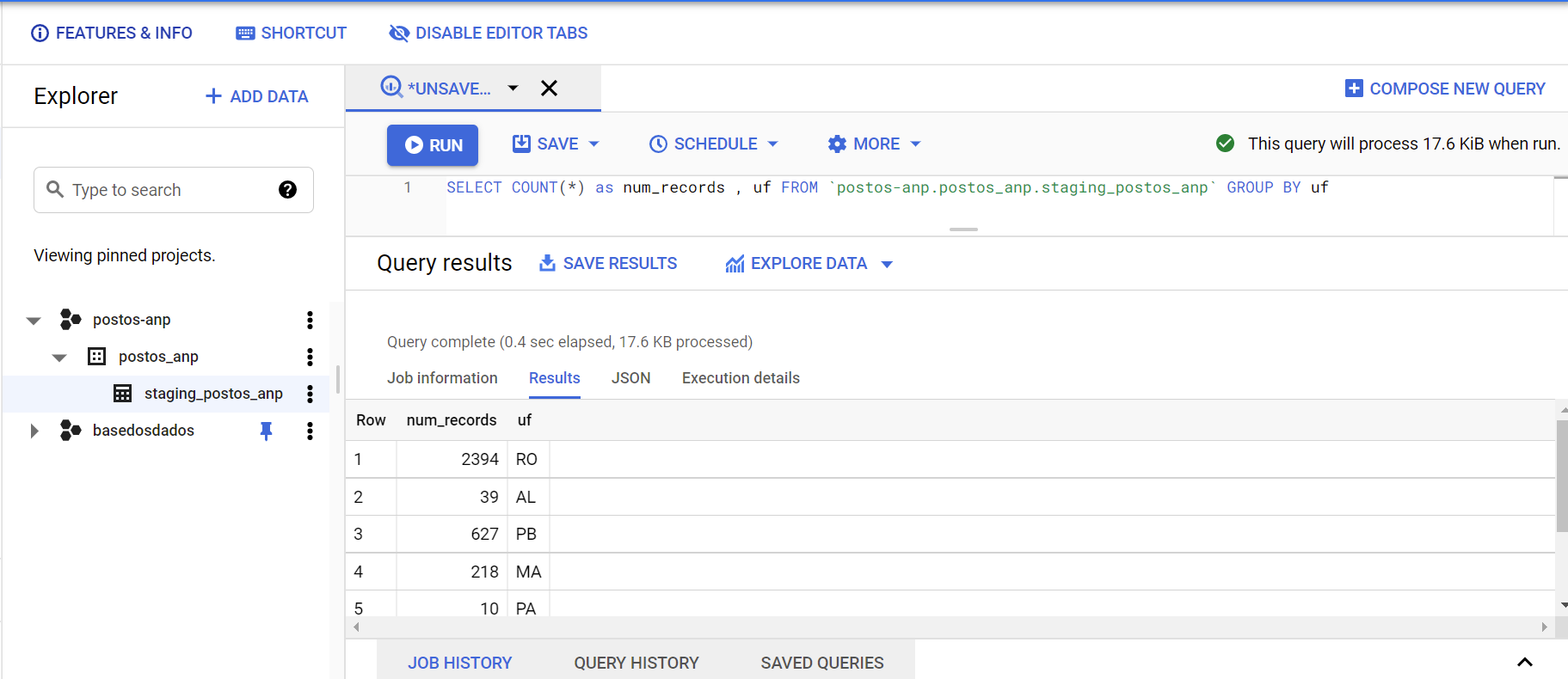
Finally, in any time we can query our table in Big Query to inspect the data collected.
4. Conclusion
WoW! That was a long run to conclude this project! But I was very satisfied! I hope you enjoy it as well. If you reached here, I very thankful to you and if you desire to talk about this project or related stuff don’t think twice, reach me soon as possible! 🤓
Github: Serverless Scrapy