
Analyzing Pipelines Performance
1. Introduction
As well known scrapy is one the most popular frameworks for web scraping regardless of the programming language. Furthermore, its core was built on top of twisted, which is a framework for asynchronous programming in python.
Until today when I have built some pipelines to persist my data in a database, for instance in MongoDB I have used some connector based on some synchronous/blocking process, like pymongo. That’s said, occurred to me if there is some significant difference if the pipeline uses an asynchronous driver for interact with the database instead of the synchronous. For evaluating such difference we’re going to use txmongo which is written using twisted.
For the purpose of this study, we’ll use scrapy-bench that is a piece of software written for benchmark analysis suggested by scrapy community.
2. Environment Setup
First of all, let’s clone the scrapy-bench repository.
git clone https://github.com/scrapy/scrapy-bench
Our next step consists of using a docker container to host locally a website Books to Scrape for our scraping test. Firstly, we’re going to build a image.
docker build -t scrapy-bench-server -f docker/Dockerfile .
and then run the container to host our locally version of the website.
docker run --rm -ti --network=host scrapy-bench-server
The usage of scrapy-bench consists of several options listed below. One of these is broadworm which uses 1000 copies of the site Books to Scrape which are dynamically generated using twisted.
Usage: scrapy-bench [OPTIONS] COMMAND1 [ARGS]... [COMMAND2 [ARGS]...]...
A benchmark suite for Scrapy.
Options:
--n-runs INTEGER Take multiple readings for the benchmark.
--only_result Display the results only.
--upload_result Upload the results to local codespeed
--book_url TEXT Use with bookworm command. The url to book.toscrape.com on
your local machine
--vmprof Profling benchmarkers with Vmprof and upload the result to
the web
-s, --set TEXT Settings to be passed to the Scrapy command. Use with the
bookworm/broadworm commands.
--help Show this message and exit.
Commands:
bookworm Spider to scrape locally hosted site
broadworm Broad crawl spider to scrape locally hosted sites
cssbench Micro-benchmark for extraction using css
csv Visit URLs from a CSV file
itemloader Item loader benchmarker
linkextractor Micro-benchmark for LinkExtractor()
urlparseprofile Urlparse benchmarker
xpathbench Micro-benchmark for extraction using xpath
Moving on in our setup we’re going to add a network mapping in /etc/hosts file. This is a necessary step for our crawler identify all domains needed to run our benchmark. There are 1000 records to add to that file and put those in manually way is out of the question. Therefore we wrote a python script to generate those texts for the required mapping to our benchmark. Thus with that done we just need copy and paste the content into /etc/hosts and that task will be done.
with open("./domain.txt", "w") as f:
for i in range(1, 1001):
f.write(f"127.0.0.1 domain{i}\n")
Our next goal is to create a virtual environment with the required dependencies for our project. However scrapy-bench project evaluates mainly aspects of the throughput of the crawling process, which may be defined based on the number of pages or items crawled per a certain amount of time, usually measured in seconds. Otherwise, our scope consists to evaluate performance on writing data in a MongoDB database based on two drivers: pymongo and txmongo, where the former is synchronous and the latter is based on an asynchronous process.
So we need to update the project dependencies and we’re going to edit edit the setup.py file.
from setuptools import setup
setup(
name='Scrapy-Benchmark',
version='1.0',
packages=['scrapy_bench'],
install_requires=[
'Click',
'scrapy',
'statistics',
'six',
'vmprof',
'colorama<=0.4.1',
'pymongo',
'txmongo',
],
entry_points='''
[console_scripts]
scrapy-bench=bench:cli
''',
)
Thereby we can install the project requirements with the following commands.
python -m venv .venv
source .venv/bin/activate
pip install --editable .
So, last but not less important we’re going to create an instance of MongoDB database. For that, I’ve written a docker compose file.
mongo:
image: mongo:3.6
container_name: mongodb
restart: always
ports:
- 27017:27017
environment:
- PUID=1000
- PGID=1000
volumes:
- ~/development/Docker/Volumes/MongoDB:/data/db
To put our database up and running we run the following command.
docker-compose -f docker-compose.yml up mongo
3. Customizing the pipeline
As we said we’re going to evaluate the performance of two connectors for MongoDB database. For that, we’ll use an extension written by Dimitrios Kouzis-Loukas which measures throughput and latencies along the process of crawling. Better than that this extension tracks the amount of time consumed of an item along the item pipeline, which in our case is the persistence of the data in MongoDB. If you are interested in checkout the full implementation of this extension you can find the code here.
Thus to activate this extension in our code base we need to include the code below in the settings.py of our scrapy project.
EXTENSIONS = {'broad.latencies.latencies.Latencies': 300}
LATENCIES_INTERVAL = 2
Moreover, we’ll customize our spider BroadBenchSpider to persist the data from Latencies extension into a file for our posterior analysis.
logname = 'sync-test.log'
#logname = 'async-test.log'
logger = logging.getLogger(name)
logger.setLevel(logging.INFO)
fh = logging.FileHandler(logname)
fh.setLevel(logging.INFO)
logger.addHandler(fh)
3.1 pymongo
We’re going to use a pipeline for pymongo available in this repository. After we created an module to host a MongoDBPipeline class which implement our pipeline to save an item in the database, we need to insert aditional configuration in settings.py in similar manner we did before.
MONGODB_URI = 'mongodb://localhost:27017'
MONGODB_DATABASE = 'scrapy'
MONGODB_COLLECTION = 'books'
ITEM_PIPELINES = {'broad.mongosync.mongosync.MongoDBPipeline': 300}
3.1.1 pymongo benchmark
For getting some reliable metrics for our analysis we’re going to run our tests with 10 replicates. So we’ll start the test by the command:
time scrapy-bench --n-runs 10 broadworm
That way our test will crawl our target website ten times which one of them will close automatically when reach 800 items collected (CLOSESPIDER_ITEMCOUNT = 800). This code will give to us some stats about throughput in ours runs. Well, that said we present below the stats for the pymongo pipeline.
The results of the benchmark are (all speeds in items/sec) :
Test = 'Broad Crawl' Iterations = '10'
Mean : 18.736101409402963 Median : 21.69220137534533 Std Dev : 7.742630114239552
real 13m17.442s
user 4m6.533s
sys 0m3.214s
With that done we can inspect a few lines of sync-test.log file which logs stats provided by the Latencies extension.
Scraped 0 items at 0.0 items/s, avg latency: 0.00 s and avg time in pipelines: 0.00 s
Scraped 50 items at 25.0 items/s, avg latency: 1.33 s and avg time in pipelines: 1.03 s
Scraped 13 items at 6.5 items/s, avg latency: 2.52 s and avg time in pipelines: 0.17 s
Scraped 16 items at 8.0 items/s, avg latency: 4.53 s and avg time in pipelines: 0.14 s
Scraped 53 items at 26.5 items/s, avg latency: 5.58 s and avg time in pipelines: 0.16 s
Scraped 70 items at 35.0 items/s, avg latency: 6.05 s and avg time in pipelines: 0.23 s
Scraped 83 items at 41.5 items/s, avg latency: 6.00 s and avg time in pipelines: 0.42 s
Scraped 81 items at 40.5 items/s, avg latency: 5.23 s and avg time in pipelines: 0.82 s
Scraped 78 items at 39.0 items/s, avg latency: 6.33 s and avg time in pipelines: 1.20 s
Scraped 86 items at 43.0 items/s, avg latency: 6.07 s and avg time in pipelines: 1.22 s
Scraped 96 items at 48.0 items/s, avg latency: 5.70 s and avg time in pipelines: 1.11 s
With this file in our hands, we’re going to analyze this log to evaluate the time spent in the pipeline stage.
dfsync = pd.read_csv("./data/sync-test.log", header=None, sep=';')
dfsync.rename(columns={0 : 'log'}, inplace=True)
dfsync[['num_items', 'throughput', 'avg_latency', 'avg_time_in_pipeline']] = dfsync['log'].apply(lambda x : re.findall("(\d+(?:\.\d+)?)", x)).tolist()
for col in ['throughput', 'avg_latency', 'avg_time_in_pipeline']:
dfsync[col] = dfsync[col].astype(float)
dfsync['num_items'] = dfsync['num_items'].astype(int)
As we could see in the following table on average our spider spent 0.42 seconds in the pipeline stage when we used pymongo as our driver to persist data in MongoDB database.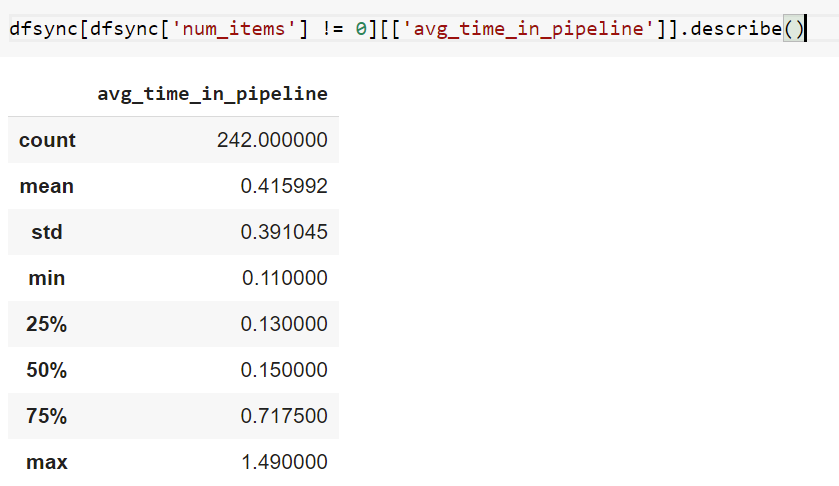
3.2 txmongo
For this driver we’re going to use an implementation for MongoDB pipeline available in this repository. First, we need to change our pipeline settings to use MongoPipeline class which implements the use of txmongo to communicate with the database.
ITEM_PIPELINES = {
#'broad.mongosync.mongosync.MongoDBPipeline': 300,
'broad.asyncpipe.pipelines.mongo.MongoPipeline': 300,
}
3.2.1 txmongo benchmark
Similarly, we’ll repeat the procedure for this test.
time scrapy-bench --n-runs 10 broadworm
After some minutes our test was done and the results are:
The results of the benchmark are (all speeds in items/sec) :
Test = 'Broad Crawl' Iterations = '10'
Mean : 20.92516241044525 Median : 21.582681058580057 Std Dev : 6.066783428367009
real 9m42.868s
user 4m23.577s
sys 0m3.396s
Analyzing the data logged by our extension we can determine the average time spent for our crawler in the spider pipeline.
dfasync = pd.read_csv("./data/async-test.log", header=None, sep=';')
dfasync.rename(columns={0 : 'log'}, inplace=True)
dfasync[['num_items', 'throughput', 'avg_latency', 'avg_time_in_pipeline']] = dfasync['log'].apply(lambda x : re.findall("(\d+(?:\.\d+)?)", x)).tolist()
for col in ['throughput', 'avg_latency', 'avg_time_in_pipeline']:
dfasync[col] = dfasync[col].astype(float)
dfasync['num_items'] = dfasync['num_items'].astype(int)
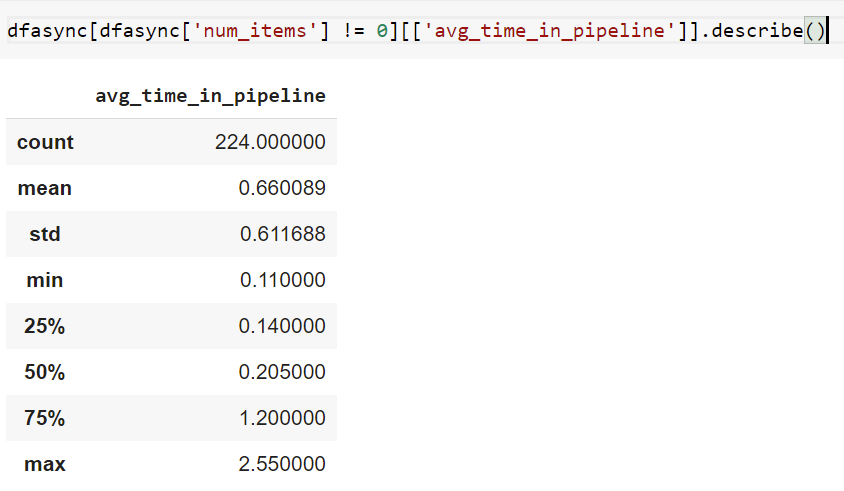
4. Results
The table bellow shows the consolidated results of our tests.
| driver | items/sec | pipeline time | benchmark overall time |
|---|---|---|---|
| pymongo | 18.74 ± 7.74 | 0.41 ± 0.39 | 13m17.442s |
| txmongo | 20.93 ± 6.07 | 0.66 ± 0.61 | 9m42.868s |
First of all, we’re going to make a statistical test called 2 sample t-test to evaluate if there is a statistical difference between a time spent in the pipeline stage of our spider when it uses pymongo or txmongo to persist data in MongoDB database. Furthermore, we’ll perform our test with a confidence interval of 95% and our null hypothesis for this test will be:
H(0) : There is no difference in the time spent in scrapy pipeline when saving data onto database when use txmongo instead of pymongo.
H(1) : There is a difference in the time spent in scrapy pipeline when saving data onto database when use txmongo instead of pymongo.
For this task, we need to select all the records when the numbers of items collected by our spider were different from zero on each test and by each sample we collect the average and standard deviation for this data.
N_pymongo = 242
N_txmongo = 224
avg_pymongo = 0.41
avg_txmongo = 0.66
std_pymongo = 0.39
std_txmongo = 0.61
df = N_pymongo + N_txmongo - 2 #degree of freedom
Then we can calculate the t-statistic for our test.
t_calc = (avg_pymongo-avg_txmongo)/np.sqrt(((std_pymongo**2)/N_pymongo)+((std_txmongo**2)/N_txmongo))
With the above calculation, we got a value of -5.224. Then we need to compare this value with the critical t-value from t-distribution. There are several sources to get this data, one of these is this site. Thus, the critical value for t is 1.97. Therefore we can’t reject the null hypothesis and there are no statistical evidence that the average time spent saving data in database is different when use txmongo instead of pymongo.
Besides that, even that we can’t identify any difference in the pipeline stage for changing our driver from pymongo to txmongo, we need to mention that the overall time consumed for our complete test (10 runs) took 794.4 seconds to complete when the test was executed with pymongo, that is approximately 36% slower when our test was runned with txmongo. Maybe this enhancement for the overall process of web scraping when we’re using txmongo, could be justified by the use of the same engine used by scrapy.
Thus I hope you have enjoyed this article the same way I have it to write it. The code used in this article can be found in this repository. See you in the next post!